
8月21日にもりけん塾で勉強会が行われました!
インターネットの仕組み~ブラウザにWebページが表示されるまでの旅~ というテーマで
発表をさせて頂きました。
この様な機会を作っていただきありがとうございました。
今回は勉強会で発表した内容をまとめた記事です。
私が学習し、知り得た範囲での内容なので
もし誤りがあればTwitterのDM等で教えていただけると嬉しいです。
経緯とテーマ
「勉強しようと思っていたけどやってなかったこと」をテーマにしました。
重たい腰を起こすためにも、自ら立候補させて頂きました。
内容に関しては、もりけん先生が以前Twitterで紹介していた
フロントエンドエンジニアになるためのロードマップ を参考に範囲を決めました。
ロードマップの紫色のチェックがついている部分を、優先して学習するのがいいそうです!
大まかな流れ
以下の様な流れで進めました

#1 Webサイトへアクセスする
今回はアドレスバーにgoogleのURLを入力しアクセスすることを仮定します

#2 ブラウザはURLの解読を始める
URLに含まれる情報の解読を行います。
どの方法で?、どのサーバーから?、どのファイル(リソース)を?などの情報がURLには含まれています。

プロトコル
通信規約、約束事。ネットワークに接続された機械同士が通信する時の共通のルールや手順のこと
FTP、SMTPなどもプロトコルの一種です。
作戦や球種を味方に伝える際、相手チームに伝わらない様に、
事前に決めたサインを使い味方に伝えます。
それらのサインも事前にチーム内で共有されているからわかる約束事です。
HTTP(HyperText Transfer Protocol)
WebクライアントとWebサーバーの通信をする際の決まり事
IPアドレス・ドメイン名
住所の様なもの。
ネットワーク上のやり取りには、識別番号としてIPアドレスが利用される。
IPアドレスは数字の羅列で表記される(例:104.20.37.67)
IPアドレスは人間が覚えにくく扱いにくい為、ドメインを利用しています。
IPアドレスはよく電話帳に例えられます。
電話やメールを送る際、相手の電話番号やアドレスを覚えていなくても、
スマホに登録していれば、アドレスと名前が紐付いている為、登録名を選択すればおのずと連絡ができます。
この登録名の役割を担っているのがドメイン名で、電話番号やメールアドレスがIPアドレスの様なイメージです。
#3 DNSでIPアドレスを取得する
ドメイン名をDNSサーバーに投げ掛け、IPアドレスを教えてもらう
FQDNからIPアドレスを割り出すことを、名前解決といいます。
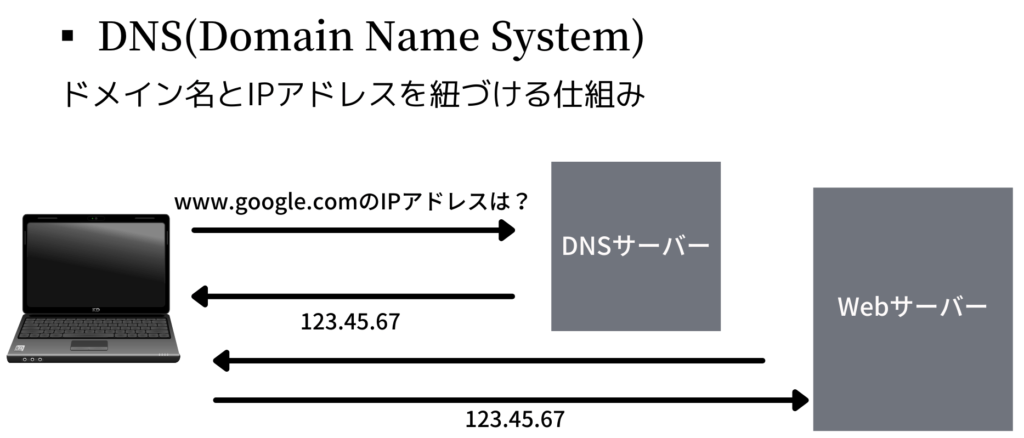
もう少し詳しく流れを調べました
DNSキャッシュサーバー
フルサービスリゾルバと呼ばれることもある。
まず自分のキャッシュを確認し、なければ他のDNSサーバーヘ問い合わせを行うサーバー。

hostsファイル
DNSが誕生する前まで主流で使われていた仕組み。
ホスト名とIPアドレスの対応表を個々のコンピューターで管理していた。
インターネットが普及し、ドメイン名も増えた為個々のhostsファイルで管理していくには限界があり
DNSが名前解決の主流となった。hostsファイルは現在も存在している。
返却されたIPアドレスをもとに、ブラウザはHTTPリクエストを作成。
#4 HTTPリクエスト / HTTPレスポンス
クライアント(Webブラウザ)からWebサーバーへ送られる要求のことを
HTTPリクエスト、そのリクエストに対する応答をHTTPレスポンスという。
ターミナルで確認してみる
HTTP通信の詳細を出力するコマンド
% curl -v https://www.google.com/HTTPリクエスト
HTTPリクエストは以下の様な構成になっています。
(左側が構造で、右側が実際のHTTPリクエストです)

リクエストラインにはメソッドを使用し、具体的に何を要求するのかを記載します。
メソッドはGET以外にもPOSTやPUTなど全部で8つあり、それぞれ違う役割を持ちます。
今回はGETを使用しています。GETは指定されたURLの情報を取得するメソッドです。
HTTPレスポンス
先ほどのリクエストに対しての応答がHTTPレスポンスです。
(左側が構造で、右側が実際のHTTPレスポンスです)

ステータスラインではステータスコードを使用し、要求に対する結果を伝えます。
今回は200というリクエストが正常に終了したことを意味するコードです。
サーバーから返ってきたレスポンスの中に
画像やCSSなどのリンクがあるとその度にリクエストを送り必要なデータをもらいます。
404はよく目にするステータスコードだと思います。
要求されたリソースが見つからない場合を示します。
#5 ブラウザレンダリング
サーバーから送られてきたHTMLファイルを解析し、レンダリング処理を行う。
ブラウザのレンダリング機能をレンダリングエンジンといい、ブラウザごと存在している。
HTMLを解析、DOM・CSSOMを構築
サーバーから送られてきたデータはBytes(バイト)という形式で送られてくる。
これではHTMLと解釈することができないため解析を行う。
まず、BytesからCharacters(文字)へ変換を行い
その後Tokens(トークン)と呼ばれる形に変換し、Nodes(ノード)へ変換後、DOMの構築を行う。
(以下の参考画像をみるとわかりやすい…)
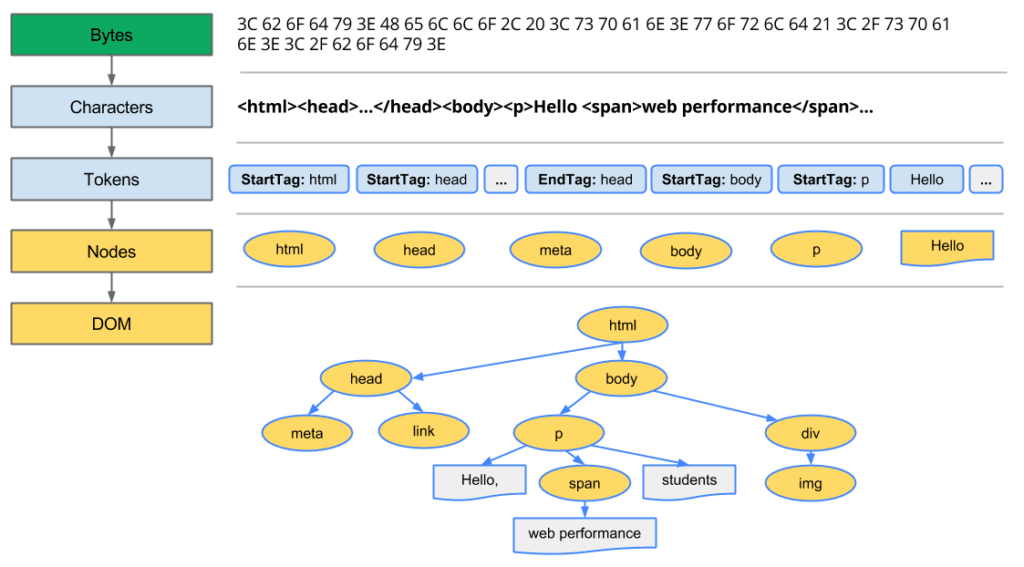
Tokens(トークン)
字句解析。
文字に変換しただけではブラウザエンジンでは意味を持たない為、
Tokens化を行い、HTMLタグに関する情報やルールを理解するプロセス。
いくつか記事を読んだのですが、あまり理解することができませんでした
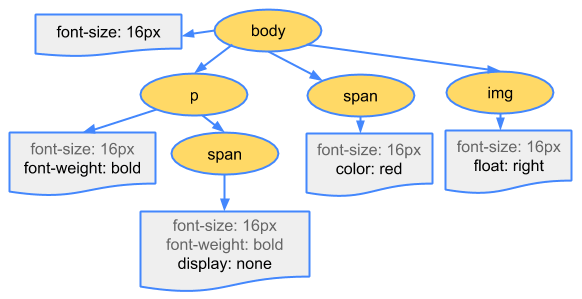
CSSOMを構築
HTMLを解析中にCSSに遭遇したら、CSSの読み込みを開始。
解析のフローはHTMLの時と同様に行い、
HTMLと違いCSSはCSSOM ( CSS Object Model ) を構築する。
カスケードダウン
どの様にスタイルを適用していくかのルール。
対象のノードに当てはまる一般的なスタイルを適用し、
より具体的なスタイルがあれば上書きし調整する。
親要素から継承したり、個々に指定されたスタイルを適用したりする為
ツリー構造にしスタイルの決定を行う。
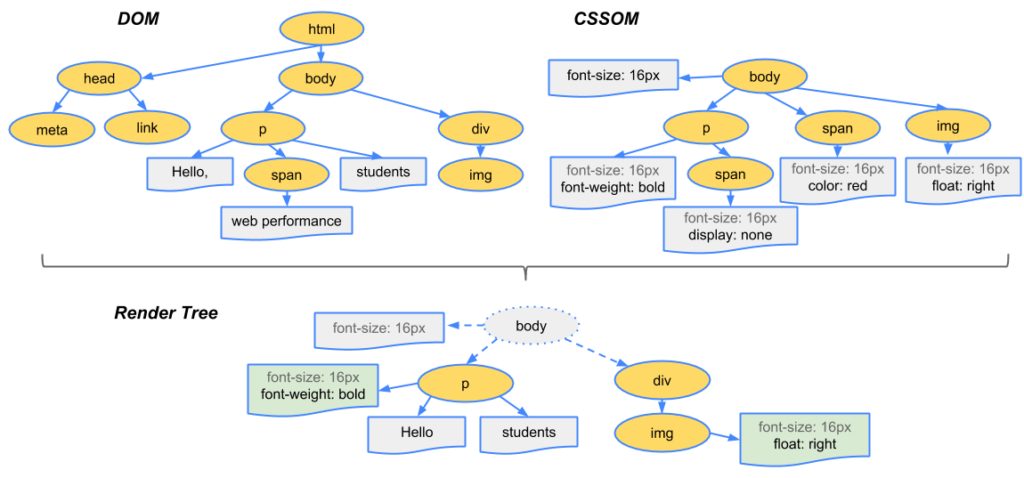
レンダリングツリーの構築
DOMとCSSOMを組み合わせ、表示可能な情報を取り込んだレンダリングツリーを構築する。
表示可能なノードを取り込むため、<head>タグやその子要素などの表示されない要素や、
CSSでdisplay:none;と指定されたノードもレンダリングの結果に影響しないため、
レンダリングツリーには含まれない。
また、visibility: hidden が適用されたノードは、スペースを確保するためにレンダリングツリーに含まれます。
レイアウト(リフロー)
レンダリングツリーに含まれる各ノードの位置やサイズを決定します。
ペイント
画面にコンテンツを表示していく。
リフローとリペイントが起きる時の例
頻繁にリフローやリペイントが起こることはコストがかかり
UIの動作に影響することは今までの学習で理解できました。
実際にどの様な時に発生するのかを幾つかまとめました。
・ノードの追加、削除、更新、移動(アニメーション)
・ノードの非表示
display: none はリフローとリペイントの両方が発生する
visibility: hidden はリペイントのみ発生する
・CSSの調整や、追加
…などが挙げられます。
脱線しましたが、
これで無事にWebサイトが表示されました。

まとめ
とても難しい内容でした…
書籍や記事によって言葉や説明が微妙に違っていたりするところや
どの様な処理がされているかのイメージがつきにくいところに苦戦しました。
レンダリングの部分は実装部分に大きく関わることだと思うので
より深い知識を持つことで、視野を広く持つことができるのでは、と感じました。
こういった学習はなかなか必要に迫られないとやらなかったりするので
勉強会で発表する機会を頂けて、学習のハードルが下がった様に思います。
今回はJavaScriptのレンダリングまで学習することができなかったので、
引き続きJavaScriptのレンダリングについて学習をしていこうと思います。
参考
– Frontend Developer Step by step guide
https://roadmap.sh/frontend/resources
– DNS
https://howdns.works/
– DOM構築
https://developers.google.com/web/fundamentals/performance/critical-rendering-path/constructing-the-object-model
– レンダリング
https://developers.google.com/web/fundamentals/performance/critical-rendering-path/render-tree-construction
https://developer.mozilla.org/ja/docs/Web/Performance/How_browsers_work#render
https://dev.to/gopal1996/understanding-reflow-and-repaint-in-the-browser-1jbg
– Webの仕組み
https://www.freecodecamp.org/news/how-the-web-works-a-primer-for-newcomers-to-web-development-or-anyone-really-b4584e63585c/#.7l3tokoh1
https://github.com/vasanthk/how-web-works#dns-lookup
https://blog.logrocket.com/how-browser-rendering-works-behind-scenes/
イラスト図解式 この一冊で全部わかるWeb技術の基本
Webを支える技術
もりけん塾でJavaScriptを学習をしています!
もりけん先生のTwitter:https://twitter.com/terrace_tech



コメント